
0x0 前言&LibFuzzer 源码审计
前言
1988年秋天的黑暗和暴风雨的夜晚中, 巴顿·米勒教授坐在麦迪逊威斯康星州的公寓里,通过一条1200波特的电话线连接到他的大学计算机。 雷暴在线路上造成噪音,而该噪音又导致两端的UNIX命令获得错误的输入并崩溃。 频繁的崩溃让他感到惊讶,他思考到,程序应该比这更强大吗? 作为一名科学家,他想调查问题的严重程度及其原因。 因此,他为威斯康星大学麦迪逊分校的学生编写了编程练习–该练习将使他的学生创建第一个模糊测试器。
许多年后,一个叫AFL的模糊测试器横空出世,一举成为这个星球上最热门的Fuzzer,能够检测到 1000 多种不同类型的软件错误。由于原始 AFL 存储库的开发长期停滞,社区于 2019 年创建了一个名为 AFL++的分支(被笔者拿去水了一次网安实践课的汇报,源码审计这一块、)
读者可能会问为什么要创建一个新的模糊测试器?答案是,AFL 无法处理不同类型的覆盖率,例如跟踪比较指令的求值(在 C 语言中==,>、<、!=等)。其次,AFL 无法跟踪根据输入返回特定值的标准(和非标准)函数的求值,例如用于比较字符串的函数(在 C 语言中strcmp(),strncmp()、 等)。最后,AFL 不够灵活,无法集成到接受来自不同来源输入的环境中standard input。
概览libfuzzer
extern "C" {
// This function should be defined by the user.
int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size);
} // extern "C"
ATTRIBUTE_INTERFACE int main(int argc, char **argv) {
return fuzzer::FuzzerDriver(&argc, &argv, LLVMFuzzerTestOneInput);
} //FuzzerMain.c
int FuzzerDriver(int *argc, char ***argv, UserCallback Callback) {
using namespace fuzzer;
assert(argc && argv && "Argument pointers cannot be nullptr");
std::string Argv0((*argv)[0]);
EF = new ExternalFunctions();
....
const Vector<std::string> Args(*argv, *argv + *argc);
assert(!Args.empty());
ProgName = new std::string(Args[0]);
if (Argv0 != *ProgName) {
Printf("ERROR: argv[0] has been modified in LLVMFuzzerInitialize\n");
exit(1);
}
ParseFlags(Args, EF);
if (Flags.help) {
PrintHelp();
return 0;
} //前面主要是参数配置和检查完整性
...
Random Rand(Seed);
auto *MD = new MutationDispatcher(Rand, Options);
auto *Corpus = new InputCorpus(Options.OutputCorpus);
auto *F = new Fuzzer(Callback, *Corpus, *MD, Options);//Fuzz对象配置
for (auto &U: Dictionary)
if (U.size() <= Word::GetMaxSize())
MD->AddWordToManualDictionary(Word(U.data(), U.size()));
StartRssThread(F, Flags.rss_limit_mb); //后台监控内存占用, 如果超了自动把进程杀掉
...
SetSignalHandler(Options);
...
auto CorporaFiles = ReadCorpora(*Inputs, ParseSeedInuts(Flags.seed_inputs));
F->Loop(CorporaFiles); //主逻辑
}
static void StartRssThread(Fuzzer *F, size_t RssLimitMb) {
if (!RssLimitMb) return;
std::thread T(RssThread, F, RssLimitMb);
T.detach();
}
重要的数据结构
namespace fuzzer { //fuzzer域
using namespace std::chrono;
class Fuzzer {
public:
Fuzzer(UserCallback CB, InputCorpus &Corpus, MutationDispatcher &MD,
FuzzingOptions Options);
~Fuzzer();
void Loop(Vector<SizedFile> &CorporaFiles); // 循环
void ReadAndExecuteSeedCorpora(Vector<SizedFile> &CorporaFiles); // 执行提供的输入样本
void MinimizeCrashLoop(const Unit &U);
void RereadOutputCorpus(size_t MaxSize);
size_t getTotalNumberOfRuns() { return TotalNumberOfRuns; }
void ExecuteCallback(const uint8_t *Data, size_t Size); // 调用CallBack
bool RunOne(const uint8_t *Data, size_t Size, bool MayDeleteFile = false,
InputInfo *II = nullptr, bool *FoundUniqFeatures = nullptr); // ExecuteCallback父函数
// Merge Corpora[1:] into Corpora[0].
void Merge(const Vector<std::string> &Corpora); // 合并
void CrashResistantMergeInternalStep(const std::string &ControlFilePath);
MutationDispatcher &GetMD() { return MD; } // 变异类
...
static void MaybeExitGracefully(); // 退出
std::string WriteToOutputCorpus(const Unit &U); // 记录
private:
...
system_clock::time_point LastAllocatorPurgeAttemptTime = system_clock::now();
UserCallback CB; //目标函数
InputCorpus &Corpus; //测试样本
MutationDispatcher &MD; //变异策略
FuzzingOptions Options; //fuzz选项
DataFlowTrace DFT; //coverage-guided fuzzing增强,追踪数据流
system_clock::time_point ProcessStartTime = system_clock::now();
system_clock::time_point UnitStartTime, UnitStopTime;
long TimeOfLongestUnitInSeconds = 0;
long EpochOfLastReadOfOutputCorpus = 0;
size_t MaxInputLen = 0;
size_t MaxMutationLen = 0;
size_t TmpMaxMutationLen = 0;
Vector<uint32_t> UniqFeatureSetTmp; //临时存储本次执行输入触发的新 coverage features
// Need to know our own thread.
static thread_local bool IsMyThread;
};
Fuzz&Mutation
void Fuzzer::Loop(Vector<SizedFile> &CorporaFiles) {
auto FocusFunctionOrAuto = Options.FocusFunction;
DFT.Init(Options.DataFlowTrace, &FocusFunctionOrAuto, CorporaFiles,
MD.GetRand()); //数据流追踪初始化
TPC.SetFocusFunction(FocusFunctionOrAuto); //覆盖率追踪初始化
ReadAndExecuteSeedCorpora(CorporaFiles); //读取种子语料库文件(CorporaFiles),并对目标程序执行这些输入
DFT.Clear(); // 清除数据流跟踪数据,表示 DFT 仅用于处理初始种子语料库
TPC.SetPrintNewPCs(Options.PrintNewCovPcs); //根据options决定是否打印新触发的ip地址
TPC.SetPrintNewFuncs(Options.PrintNewCovFuncs); //根据options决定是否打印新遍历的Func名称
system_clock::time_point LastCorpusReload = system_clock::now(); //记录当前时间
TmpMaxMutationLen =Min(MaxMutationLen, Max(size_t(4), Corpus.MaxInputSize())); //初始化变异长度,默认为4
while (true) {
//检查终止条件
auto Now = system_clock::now();
if (!Options.StopFile.empty() &&
!FileToVector(Options.StopFile, 1, false).empty())
break;
if (duration_cast<seconds>(Now - LastCorpusReload).count() >=
Options.ReloadIntervalSec) {
RereadOutputCorpus(MaxInputLen);
LastCorpusReload = system_clock::now();
}
if (TotalNumberOfRuns >= Options.MaxNumberOfRuns)
break;
if (TimedOut())
break;
// 动态调整变异长度 -- 这一机制在早期使用较小的变异以探索代码路径,后期逐渐增加变异长度以进行更深入的测试
if (Options.LenControl) {
if (TmpMaxMutationLen < MaxMutationLen &&
TotalNumberOfRuns - LastCorpusUpdateRun >
Options.LenControl * Log(TmpMaxMutationLen)) {
TmpMaxMutationLen =
Min(MaxMutationLen, TmpMaxMutationLen + Log(TmpMaxMutationLen));
LastCorpusUpdateRun = TotalNumberOfRuns;
}
} else {
TmpMaxMutationLen = MaxMutationLen; // 不动态调整,那就直接最大数量变异
}
// 进行变异然后运行
MutateAndTestOne();
PurgeAllocator();
}
PrintStats("DONE ", "\n");
MD.PrintRecommendedDictionary();
}
DFT.Init(先鸽着x,没细看)
bool DataFlowTrace::Init(const std::string &DirPath, std::string *FocusFunction,
Vector<SizedFile> &CorporaFiles, Random &Rand) {
if (DirPath.empty()) return false;
Printf("INFO: DataFlowTrace: reading from '%s'\n", DirPath.c_str());
Vector<SizedFile> Files;
GetSizedFilesFromDir(DirPath, &Files);
std::string L;
size_t FocusFuncIdx = SIZE_MAX;
Vector<std::string> FunctionNames;
// Collect the hashes of the corpus files.
for (auto &SF : CorporaFiles)
CorporaHashes.insert(Hash(FileToVector(SF.File))); // 储存文件的hash
// Read functions.txt
std::ifstream IF(DirPlusFile(DirPath, kFunctionsTxt));
size_t NumFunctions = 0;
while (std::getline(IF, L, '\n')) {
FunctionNames.push_back(L);
NumFunctions++;
if (*FocusFunction == L)
FocusFuncIdx = NumFunctions - 1;
}
if (!NumFunctions)
return false;
if (*FocusFunction == "auto") { // 自动计算得出焦点函数
// AUTOFOCUS works like this:
// * 从 DFT 文件中读取覆盖率数据。
// * 根据覆盖率给函数分配权重。
// * 根据权重选择一个随机函数。
ReadCoverage(DirPath);
auto Weights = Coverage.FunctionWeights(NumFunctions); // 给函数计算权重
Vector<double> Intervals(NumFunctions + 1);
std::iota(Intervals.begin(), Intervals.end(), 0); // 区间数组
auto Distribution = std::piecewise_constant_distribution<double>(
Intervals.begin(), Intervals.end(), Weights.begin()); // 根据权重排序
FocusFuncIdx = static_cast<size_t>(Distribution(Rand));
*FocusFunction = FunctionNames[FocusFuncIdx]; // 随机选择焦点函数
assert(FocusFuncIdx < NumFunctions);
Printf("INFO: AUTOFOCUS: %zd %s\n", FocusFuncIdx,
FunctionNames[FocusFuncIdx].c_str());
for (size_t i = 0; i < NumFunctions; i++) {
if (!Weights[i]) continue;
Printf(" [%zd] W %g\tBB-tot %u\tBB-cov %u\tEntryFreq %u:\t%s\n", i,
Weights[i], Coverage.GetNumberOfBlocks(i),
Coverage.GetNumberOfCoveredBlocks(i), Coverage.GetCounter(i, 0),
FunctionNames[i].c_str());
}
}
if (!NumFunctions || FocusFuncIdx == SIZE_MAX || Files.size() <= 1)
return false;
// Read traces.
size_t NumTraceFiles = 0;
size_t NumTracesWithFocusFunction = 0;
for (auto &SF : Files) {
auto Name = Basename(SF.File);
if (Name == kFunctionsTxt) continue;
if (!CorporaHashes.count(Name)) continue; // not in the corpus.
NumTraceFiles++;
// Printf("=== %s\n", Name.c_str());
std::ifstream IF(SF.File);
while (std::getline(IF, L, '\n')) {
size_t FunctionNum = 0;
std::string DFTString;
if (ParseDFTLine(L, &FunctionNum, &DFTString) &&
FunctionNum == FocusFuncIdx) {
NumTracesWithFocusFunction++;
if (FunctionNum >= NumFunctions)
return ParseError("N is greater than the number of functions", L);
Traces[Name] = DFTStringToVector(DFTString);
// Print just a few small traces.
if (NumTracesWithFocusFunction <= 3 && DFTString.size() <= 16)
Printf("%s => |%s|\n", Name.c_str(), std::string(DFTString).c_str());
break; // No need to parse the following lines.
}
}
}
Printf("INFO: DataFlowTrace: %zd trace files, %zd functions, "
"%zd traces with focus function\n",
NumTraceFiles, NumFunctions, NumTracesWithFocusFunction);
return NumTraceFiles > 0;
}
ReadAndExecuteSeedCorpora
void Fuzzer::ReadAndExecuteSeedCorpora(Vector<SizedFile> &CorporaFiles) {
const size_t kMaxSaneLen = 1 << 20;
const size_t kMinDefaultLen = 4096; // 默认4096
size_t MaxSize = 0;
size_t MinSize = -1;
size_t TotalSize = 0;
for (auto &File : CorporaFiles) {
MaxSize = Max(File.Size, MaxSize);
MinSize = Min(File.Size, MinSize);
TotalSize += File.Size;
}
if (Options.MaxLen == 0)
SetMaxInputLen(std::min(std::max(kMinDefaultLen, MaxSize), kMaxSaneLen));
assert(MaxInputLen > 0);
// Test the callback with empty input and never try it again.
uint8_t dummy = 0;
ExecuteCallback(&dummy, 0); //执行Fuzzer->CB, 输入为空
if (CorporaFiles.empty()) {
Printf("INFO: A corpus is not provided, starting from an empty corpus\n");
Unit U({'\n'}); // Valid ASCII input.
RunOne(U.data(), U.size()); //发一个换行符试试
} else {
Printf("INFO: seed corpus: files: %zd min: %zdb max: %zdb total: %zdb"
" rss: %zdMb\n",
CorporaFiles.size(), MinSize, MaxSize, TotalSize, GetPeakRSSMb());
if (Options.ShuffleAtStartUp)
std::shuffle(CorporaFiles.begin(), CorporaFiles.end(), MD.GetRand()); // 重组CorporaFiles?
if (Options.PreferSmall) {
std::stable_sort(CorporaFiles.begin(), CorporaFiles.end()); //从小往大开始变异corporaFiles
assert(CorporaFiles.front().Size <= CorporaFiles.back().Size);
}
// 逐个执行测试用例
for (auto &SF : CorporaFiles) {
auto U = FileToVector(SF.File, MaxInputLen, /*ExitOnError=*/false);
assert(U.size() <= MaxInputLen);
RunOne(U.data(), U.size());
CheckExitOnSrcPosOrItem();
TryDetectingAMemoryLeak(U.data(), U.size(),
/*DuringInitialCorpusExecution*/ true); // 尝试检查是否有内存非法访问
}
}
PrintStats("INITED");
if (!Options.FocusFunction.empty())
Printf("INFO: %zd/%zd inputs touch the focus function\n",
Corpus.NumInputsThatTouchFocusFunction(), Corpus.size());
if (!Options.DataFlowTrace.empty())
Printf("INFO: %zd/%zd inputs have the Data Flow Trace\n",
Corpus.NumInputsWithDataFlowTrace(), Corpus.size());
if (Corpus.empty() && Options.MaxNumberOfRuns) {
Printf("ERROR: no interesting inputs were found. "
"Is the code instrumented for coverage? Exiting.\n");
exit(1);
}
}
Fuzzer::MutateAndTestOne 主要逻辑
void Fuzzer::MutateAndTestOne() {
MD.StartMutationSequence();
auto &II = Corpus.ChooseUnitToMutate(MD.GetRand()); // 选择一个Unit作为输入进行变异
if (Options.DoCrossOver) // 交叉编译--多选一个Unit作为种子一起变异
MD.SetCrossOverWith(&Corpus.ChooseUnitToMutate(MD.GetRand()).U);
const auto &U = II.U; // U是数据
memcpy(BaseSha1, II.Sha1, sizeof(BaseSha1)); // 存储hash值
assert(CurrentUnitData);
size_t Size = U.size();
assert(Size <= MaxInputLen && "Oversized Unit");
memcpy(CurrentUnitData, U.data(), Size); // CurrentUnitData当前数据作为变异的基础,也用于存储变异后的数据
assert(MaxMutationLen > 0);
size_t CurrentMaxMutationLen = Min(MaxMutationLen, Max(U.size(), TmpMaxMutationLen)); // 最大变异长度
assert(CurrentMaxMutationLen > 0);
for (int i = 0; i < Options.MutateDepth; i++) { // 对选中的输入进行最多 Options.MutateDepth 次变异和测试
if (TotalNumberOfRuns >= Options.MaxNumberOfRuns)
break;
MaybeExitGracefully();
size_t NewSize = 0;
if (II.HasFocusFunction && !II.DataFlowTraceForFocusFunction.empty() &&
Size <= CurrentMaxMutationLen) // 优先使用数据流引导的变异(如果可用),否则使用默认变异。
NewSize = MD.MutateWithMask(CurrentUnitData, Size, Size,
II.DataFlowTraceForFocusFunction);
if (!NewSize) // 默认变异
NewSize = MD.Mutate(CurrentUnitData, Size, CurrentMaxMutationLen);
assert(NewSize > 0 && "Mutator returned empty unit");
assert(NewSize <= CurrentMaxMutationLen && "Mutator return oversized unit");
Size = NewSize;
II.NumExecutedMutations++;
bool FoundUniqFeatures = false;
bool NewCov = RunOne(CurrentUnitData, Size, /*MayDeleteFile=*/true, &II,
&FoundUniqFeatures); //
TryDetectingAMemoryLeak(CurrentUnitData, Size,
/*DuringInitialCorpusExecution*/ false); //尝试查找内存错误访问
if (NewCov) {
ReportNewCoverage(&II, {CurrentUnitData, CurrentUnitData + Size});
break; // We will mutate this input more in the next rounds.
}
if (Options.ReduceDepth && !FoundUniqFeatures)
break;
}
}
Mutate
MutationDispatcher::MutationDispatcher(Random &Rand,
const FuzzingOptions &Options)
: Rand(Rand), Options(Options) {
DefaultMutators.insert(
DefaultMutators.begin(),
{
{&MutationDispatcher::Mutate_EraseBytes, "EraseBytes"}, // 去除Bytes
{&MutationDispatcher::Mutate_InsertByte, "InsertByte"}, // 插入Bytes
{&MutationDispatcher::Mutate_InsertRepeatedBytes, //插入重复Bytes
"InsertRepeatedBytes"},
{&MutationDispatcher::Mutate_ChangeByte, "ChangeByte"}, //改变Bytes
{&MutationDispatcher::Mutate_ChangeBit, "ChangeBit"}, //改变Bit
{&MutationDispatcher::Mutate_ShuffleBytes, "ShuffleBytes"}, // 打乱某一段字节
{&MutationDispatcher::Mutate_ChangeASCIIInteger, "ChangeASCIIInt"}, // 修改 ASCII 数字串
{&MutationDispatcher::Mutate_ChangeBinaryInteger, "ChangeBinInt"}, // 修改二进制整数
{&MutationDispatcher::Mutate_CopyPart, "CopyPart"}, // 复制一部分到另一部分
{&MutationDispatcher::Mutate_CrossOver, "CrossOver"}, // 交换位置
{&MutationDispatcher::Mutate_AddWordFromManualDictionary,
"ManualDict"}, // 从手动字典里取一个词加入输入
{&MutationDispatcher::Mutate_AddWordFromPersistentAutoDictionary,
"PersAutoDict"}, // 从自动字典里取一个词加入输入
});
if(Options.UseCmp) // 用程序里比较指令(cmp/strcmp/memcmp)的信息,指导输入修改,更快的绕过if(strcmp(a,b))
DefaultMutators.push_back(
{&MutationDispatcher::Mutate_AddWordFromTORC, "CMP"});
if (EF->LLVMFuzzerCustomMutator) // 支持用户定义 LLVMFuzzerCustomMutator() 函数
Mutators.push_back({&MutationDispatcher::Mutate_Custom, "Custom"});
else
Mutators = DefaultMutators; // 否则默认
if (EF->LLVMFuzzerCustomCrossOver) // LLVMFuzzerCustomCrossOver()逻辑,交叉输入
Mutators.push_back(
{&MutationDispatcher::Mutate_CustomCrossOver, "CustomCrossOver"});
}
struct Mutator {
size_t (MutationDispatcher::*Fn)(uint8_t *Data, size_t Size, size_t Max); // 指向vtable里函数
const char *Name;
};
emmm….0_o
size_t MutationDispatcher::Mutate(uint8_t *Data, size_t Size, size_t MaxSize) {
return MutateImpl(Data, Size, MaxSize, Mutators);
}
size_t MutationDispatcher::MutateImpl(uint8_t *Data, size_t Size,
size_t MaxSize,
Vector<Mutator> &Mutators) {
assert(MaxSize > 0);
// Some mutations may fail (e.g. can't insert more bytes if Size == MaxSize),
// in which case they will return 0.
// Try several times before returning un-mutated data.
for (int Iter = 0; Iter < 100; Iter++) {
auto M = Mutators[Rand(Mutators.size())]; // 随机选一个变异方法
size_t NewSize = (this->*(M.Fn))(Data, Size, MaxSize);
if (NewSize && NewSize <= MaxSize) {
if (Options.OnlyASCII)
ToASCII(Data, NewSize); // 如果配置了 OnlyASCII,就把数据转成 ASCII(避免不可打印字符)
CurrentMutatorSequence.push_back(M); // 把这个 mutator 记录到 CurrentMutatorSequence(方便调试或复现)
return NewSize;
}
}
*Data = ' ';
return 1; // Fallback, should not happen frequently.
}
还有另一个
size_t MutationDispatcher::MutateWithMask(uint8_t *Data, size_t Size,
size_t MaxSize,
const Vector<uint8_t> &Mask) {
size_t MaskedSize = std::min(Size, Mask.size());
// 采用写回法,先复制出要变异的数据,然后变异后写回
auto &T = MutateWithMaskTemp;
if (T.size() < Size)
T.resize(Size);
size_t OneBits = 0;
for (size_t I = 0; I < MaskedSize; I++)
if (Mask[I]) // 只对mask标记为1的进行变异
T[OneBits++] = Data[I];
if (!OneBits) return 0;
assert(!T.empty());
size_t NewSize = Mutate(T.data(), OneBits, OneBits);
assert(NewSize <= OneBits);
(void)NewSize;
// Even if NewSize < OneBits we still use all OneBits bytes.
for (size_t I = 0, J = 0; I < MaskedSize; I++)
if (Mask[I])
Data[I] = T[J++]; // 写回
return Size;
}
Run
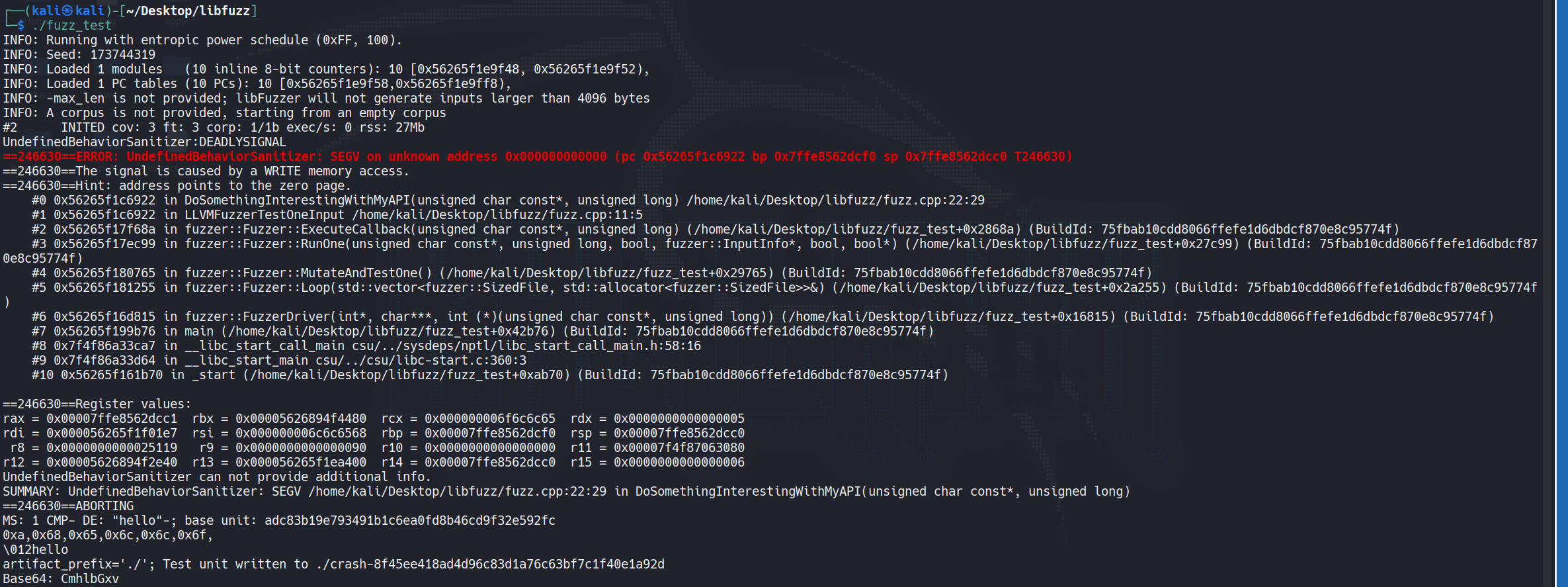
run的代码可能有点乱,审计前我们首先要意识到所有的覆盖率信息都是由编译插桩后的代码生成的,如下执行后带入ida进行反编译
┌──(kali㉿kali)-[~/Desktop/libfuzz]
└─$ clang -g -O1 -fsanitize=fuzzer -fsanitize-coverage=trace-pc fuzz.cpp -o fuzz_test

其中我们可以看到程序被插入了很多Sanitizer Coverage call gadget,这些插入的调用会在每次执行的时候记录信息,那么,这些信息是如何被记录的呢?别忘了,libfuzzer的本质是让Fuzzer和program跑在同一个进程,那么相应的信息应该会直接被记录到特征结构体等等…(猜的,但估计八九不离十)
bool Fuzzer::RunOne(const uint8_t *Data, size_t Size, bool MayDeleteFile,
InputInfo *II, bool *FoundUniqFeatures) {
if (!Size)
return false;
ExecuteCallback(Data, Size); // 执行
UniqFeatureSetTmp.clear();
size_t FoundUniqFeaturesOfII = 0; // 初始化计数器,用来记录当前输入 Data 覆盖了多少 已知输入 II 的特征
size_t NumUpdatesBefore = Corpus.NumFeatureUpdates(); // 记录 corpus 中已有的特征数量
TPC.CollectFeatures([&](size_t Feature) { // 调用 TPC(Trace PC Collector)去收集覆盖特征
if (Corpus.AddFeature(Feature, Size, Options.Shrink)) // 增加特征
UniqFeatureSetTmp.push_back(Feature);
if (Options.ReduceInputs && II) // 如果设置了精简已有输入
if (std::binary_search(II->UniqFeatureSet.begin(),
II->UniqFeatureSet.end(), Feature))
FoundUniqFeaturesOfII++; // 计数器计算
});
if (FoundUniqFeatures)
*FoundUniqFeatures = FoundUniqFeaturesOfII;
PrintPulseAndReportSlowInput(Data, Size); // 打印一些运行时的调试信息
size_t NumNewFeatures = Corpus.NumFeatureUpdates() - NumUpdatesBefore; // 新的特征个数
if (NumNewFeatures) {
TPC.UpdateObservedPCs(); // 不为0的话更新PC记录
auto NewII = Corpus.AddToCorpus({Data, Data + Size}, NumNewFeatures,
MayDeleteFile, TPC.ObservedFocusFunction(),
UniqFeatureSetTmp, DFT, II); // 把这个新输入加入 corpus
WriteFeatureSetToFile(Options.FeaturesDir, Sha1ToString(NewII->Sha1),
NewII->UniqFeatureSet);
return true;
}
if (II && FoundUniqFeaturesOfII && // 当前输入是尝试替换已有输入
II->DataFlowTraceForFocusFunction.empty() && // 没有数据流约束
FoundUniqFeaturesOfII == II->UniqFeatureSet.size() &&
II->U.size() > Size) {
auto OldFeaturesFile = Sha1ToString(II->Sha1);
Corpus.Replace(II, {Data, Data + Size}); // 直接替换
RenameFeatureSetFile(Options.FeaturesDir, OldFeaturesFile,
Sha1ToString(II->Sha1));
return true;
}
return false;
}
void Fuzzer::ExecuteCallback(const uint8_t *Data, size_t Size) {
TPC.RecordInitialStack(); // 记录当前线程的栈底
TotalNumberOfRuns++; // 统计Fuzz执行次数
assert(InFuzzingThread());
// 将输入拷贝到堆上,避免直接在原始缓冲区上操作。
uint8_t *DataCopy = new uint8_t[Size];
memcpy(DataCopy, Data, Size);
if (EF->__msan_unpoison)
EF->__msan_unpoison(DataCopy, Size); // 如果启用了 MemorySanitizer,这里会把 DataCopy 标记为“已初始化”
if (EF->__msan_unpoison_param)
EF->__msan_unpoison_param(2);
if (CurrentUnitData && CurrentUnitData != Data)
memcpy(CurrentUnitData, Data, Size);
CurrentUnitSize = Size; // 跟踪当前输入
{
ScopedEnableMsanInterceptorChecks S; // 作用域内启用 MSan interceptor 检查,自动检测未初始化内存访问
AllocTracer.Start(Options.TraceMalloc); // 启动堆分配追踪,记录 malloc/free 的匹配情况
UnitStartTime = system_clock::now();
TPC.ResetMaps();
RunningUserCallback = true;
int Res = CB(DataCopy, Size); // 调用
RunningUserCallback = false;
UnitStopTime = system_clock::now();
(void)Res;
assert(Res == 0); // 正常返回
HasMoreMallocsThanFrees = AllocTracer.Stop();
}
if (!LooseMemeq(DataCopy, Data, Size))
CrashOnOverwrittenData(); // 检查堆溢出 / 数据是否被篡改
CurrentUnitSize = 0;
delete[] DataCopy;
}
Customize ur libFuzzer!
您可以参考下面的demo,我们可以通过自定义变异入口定制自己的Fuzzer
extern "C" size_t LLVMFuzzerCustomMutator(uint8_t *Data, size_t Size,
size_t MaxSize, unsigned int Seed) {
// 先用 libFuzzer 自带的变异逻辑生成一个基础变异
Size = LLVMFuzzerMutate(Data, Size, MaxSize);
// 在结果上叠加你自己的规则,比如强行插入一个特殊 header
if (Size + 4 < MaxSize) {
memmove(Data + 4, Data, Size);
memcpy(Data, "MAGC", 4);
Size += 4;
}
return Size;
}
0x1 What‘s more???
接下来笔者准备亲自以一个大型库为开端给大家演示(and自己练习)一下挖洞客们如何跑自己的Fuzzer的
项目内Fuzz
example1

https://github.com/cisco/libsrtp,这是思科自己实现的srtp流媒体协议库,我们以它为例进行分析与测试
在(https://github.com/cisco/libsrtp/tree/main/fuzzer)[https://github.com/cisco/libsrtp/tree/main/fuzzer]这里,我们可以看到思科慷慨的提供了fuzzer目录,里面可以看到libfuzzer进行fuzz的方法以及它们已经开发完成的harness,这是典型的项目内Fuzz:将libFuzzer直接嵌入库里头生成一个可执行文件。
libsrt fuzzer
By Guido Vranken guidovranken@gmail.com – https://guidovranken.wordpress.com/
This is an advanced fuzzer for libSRTP (https://github.com/cisco/libsrtp). It implements several special techniques, described below, that are not often found in fuzzers or elsewhere. All are encouraged to transpose these ideas to their own fuzzers for the betterment of software security.
Feel free to contact me for business enquiries.
Building
From the repository’s root directory:
CC=clang CXX=clang++ CXXFLAGS="-fsanitize=fuzzer-no-link,address,undefined -g -O3" CFLAGS="-fsanitize=fuzzer-no-link,address,undefined -g -O3" LDFLAGS="-fsanitize=fuzzer-no-link,address,undefined" ./configure LIBFUZZER="-fsanitize=fuzzer" make srtp-fuzzer
运行后直接进入Fuzz目录启动strp_fuzzer,您可以看到如下场景:
构建的时候是先插桩,不加入LibFuzzer Runtime
CXXFLAGS = "-fsanitize=fuzzer-no-link,address,undefined -g -O3"
LIBFUZZER="-fsanitize=fuzzer" make srtp-fuzzer
这时候才把LibFuzzer RunTime加入其中,我看了一下Makefile,它大概是这样整的
┌──(kali㉿kali)-[~/Desktop/libsrtp]
└─$ cat Makefile | grep fuzz
CFLAGS = -fsanitize=fuzzer-no-link,address,undefined -g -O3 -fPIC -Wno-language-extension-token
CXXFLAGS= -fsanitize=fuzzer-no-link,address,undefined -g -O3
srtp-fuzzer: CFLAGS += -g
srtp-fuzzer: CXXFLAGS += -g
LDFLAGS = -L. -fsanitize=fuzzer-no-link,address,undefined
# fuzzer
srtp-fuzzer: libsrtp3.a
$(MAKE) -C fuzzer
$(MAKE) -C fuzzer clean
所以这么做本质是防止如果你在全局 CFLAGS/CXXFLAGS 就加 -fsanitize=fuzzer,那么每个 .o 都会尝试“链接 libFuzzer runtime”。剩下的基本就是它如何写harness和fuzz了,这个因人而异,不同项目也会有各种区别,就不多赘述了。
example2
找了一个CVE凑合看吧https://github.com/tarantool/tarantool/blob/master/test/fuzz/datetime_strptime_fuzzer.cc
发现者好像还是隔壁北航的,先膜一波orzorz。
#!/bin/bash -eu
git clone https://github.com/tarantool/tarantool.git --recursive
cd tarantool
git submodule update --init --recursive
export CC="clang"
export CXX="clang++"
export CFLAGS="-fsanitize=address -g -O0 -fno-omit-frame-pointer"
export CXXFLAGS="-fsanitize=address -g -O0 -fno-omit-frame-pointer -stdlib=libc++"
export LIB_FUZZING_ENGINE="-fsanitize=fuzzer"
export LSAN_OPTIONS="verbosity=1:log_threads=1"
: ${LD:="${CXX}"}
: ${LDFLAGS:="${CXXFLAGS}"}
cmake_args=(
-DENABLE_BACKTRACE=OFF
-DENABLE_FUZZER=ON
-DOSS_FUZZ=ON
-DLUA_USE_APICHECK=ON
-DLUA_USE_ASSERT=ON
-DLUAJIT_USE_SYSMALLOC=ON
-DLUAJIT_ENABLE_GC64=ON
-DCMAKE_C_COMPILER="${CC}"
-DCMAKE_C_FLAGS="${CFLAGS} -Wno-error=unused-command-line-argument"
-DCMAKE_CXX_COMPILER="${CXX}"
-DCMAKE_CXX_FLAGS="${CXXFLAGS} -Wno-error=unused-command-line-argument"
-DCMAKE_LINKER="${LD}"
-DCMAKE_EXE_LINKER_FLAGS="${LDFLAGS}"
-DCMAKE_MODULE_LINKER_FLAGS="${LDFLAGS}"
-DCMAKE_SHARED_LINKER_FLAGS="${LDFLAGS}"
-DENABLE_BUNDLED_ICU=ON
-DENABLE_BUNDLED_LIBUNWIND=OFF
-DENABLE_BUNDLED_ZSTD=OFF
)
[[ -e build ]] && rm -rf build
cmake "${cmake_args[@]}" -S . -B build
cmake --build build --target datetime_strptime_fuzzer -j$(nproc)
wget https://github.com/user-attachments/files/19613858/tarantool_crash.txt
./build/test/fuzz/datetime_strptime_fuzzer tarantool_crash.txt
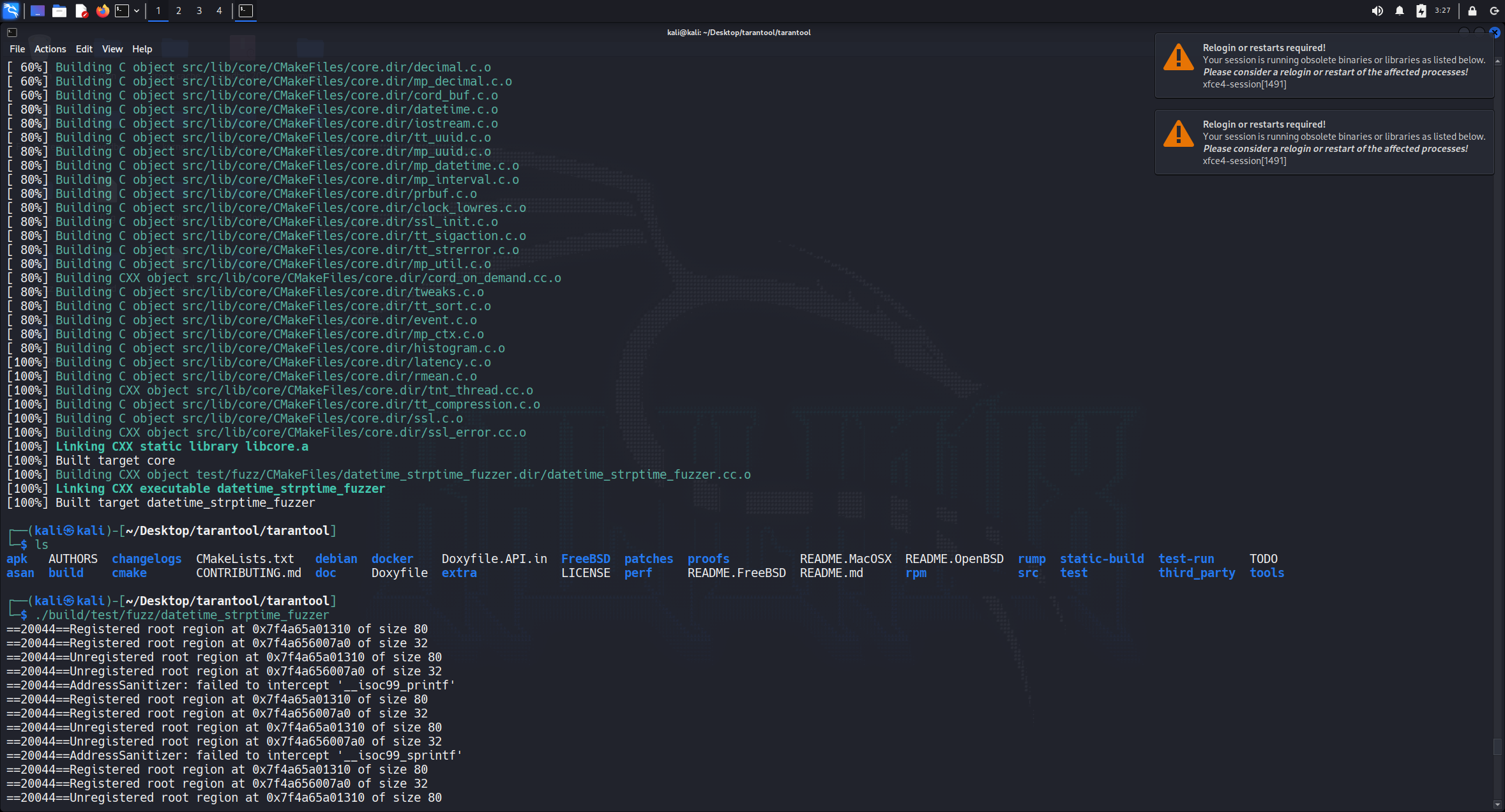
#include <fuzzer/FuzzedDataProvider.h>
#include <stddef.h>
#include "datetime.h"
extern "C" void
cord_on_yield(void) {}
extern "C" int
LLVMFuzzerTestOneInput(const uint8_t *data, size_t size)
{
FuzzedDataProvider fdp(data, size);
auto buf = fdp.ConsumeRandomLengthString();
auto fmt = fdp.ConsumeRandomLengthString();
struct datetime date_expected;
datetime_strptime(&date_expected, buf.c_str(), fmt.c_str());
return 0;
}
而且这个洞好像还没修(),
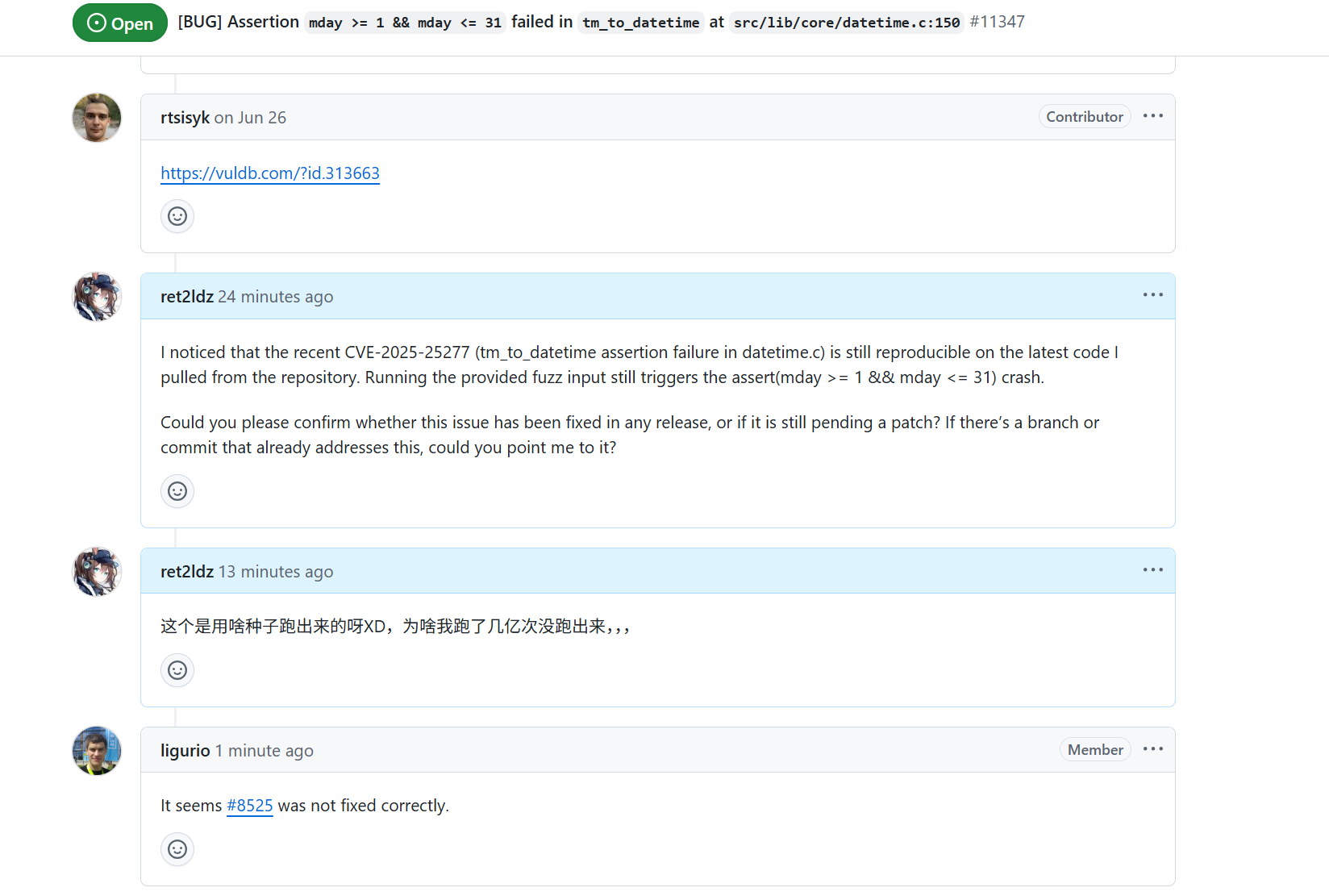
而且这哥们儿好幸运,居然能跑出crash,我这边跑了半个小时啥也没出,,,
0x2 At Last
是时候学一下cmake了…