
成为kernel高手的道路还很漫长…,吾将上下而求索:)
内存管理
虚拟内存层面
Linux_Virtual_Memory(each process)
//kernel mode:0xFFFF 8000 .... .... --0xFFFF FFFF FFFF FFFF //前16位置1,128G
...
code memory(代码段) //code,bss,data都在这里
canonical
virtual memory(也叫vmemmap区) //存放页表
canonical
vmalloc memory(动态分配的内存) //逻辑连续,但是物理地址不连续的内存被分配到这里
canonical
DMA memory(直接内存映射) //针对其有ret2dir攻击
8T canonical(空洞)
//user mode:0x0000 0000 0000 0000 -- 0x0000 7FFF FFFF FFFF //前16位置0,128G
stack.
dynamic_linked_files.
heap.
bss.
data.
code.
mm_struct
struct mm_struct {
unsigned long task_size; // 用户态大小/用户态与内核态分界线
unsigned long start_code, end_code, start_data, end_data; //用户态各个段的起始和结束地址
unsigned long start_brk, brk, start_stack; //brk的起始和结束地址,brk通过修改这个来分配堆块
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long mmap_base; /* base of mmap area */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; //数据段对应的vma
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; //栈对应的 vma
...
struct vm_area_struct *mmap; //vma的链表
}
vm_area_struct
struct vm_area_struct {
struct vm_area_struct *vm_next, *vm_prev; //vma链表指针
struct rb_node vm_rb;
struct list_head anon_vma_chain;
struct mm_struct *vm_mm; /* The address space we belong to. */
unsigned long vm_start; //这个区域的起始地址
unsigned long vm_end; //区域的结束地址
within vm_mm. */
pgprot_t vm_page_prot;
unsigned long vm_flags; //vma的权限
struct file * vm_file; //vma映射的文件
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
void * vm_private_data; /* was vm_pte (shared mem) */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
struct list_head anon_vma_chain;//反向映射,指向anon_vma_list
struct anon_vma *anon_vma; //struct_page指向anon_vma使得vma和page可以对应起来
}
当进程在向内核申请内存的时候,内核首先会为进程申请的这块内存创建初始化一段虚拟内存区域 struct vm_area_struct 结构,但是并不会为其分配真正的物理内存。当进程开始访问这段虚拟内存时,内核会产生缺页中断,在缺页中断处理函数中才会去真正的分配物理内存(这时才会为子进程创建自己的 anon_vma 和 anon_vma_chain),并建立虚拟内存与物理内存之间的映射关系(正向映射)。
struct anon_vma {
struct anon_vma *root; /* Root of this anon_vma tree */
struct rw_semaphore rwsem;
atomic_t refcount;
unsigned degree;
struct anon_vma *parent; /* Parent of this anon_vma */
struct rb_root rb_root; /* Interval tree of private "related" vmas */
};
物理内存层面
贴一张图,侵删
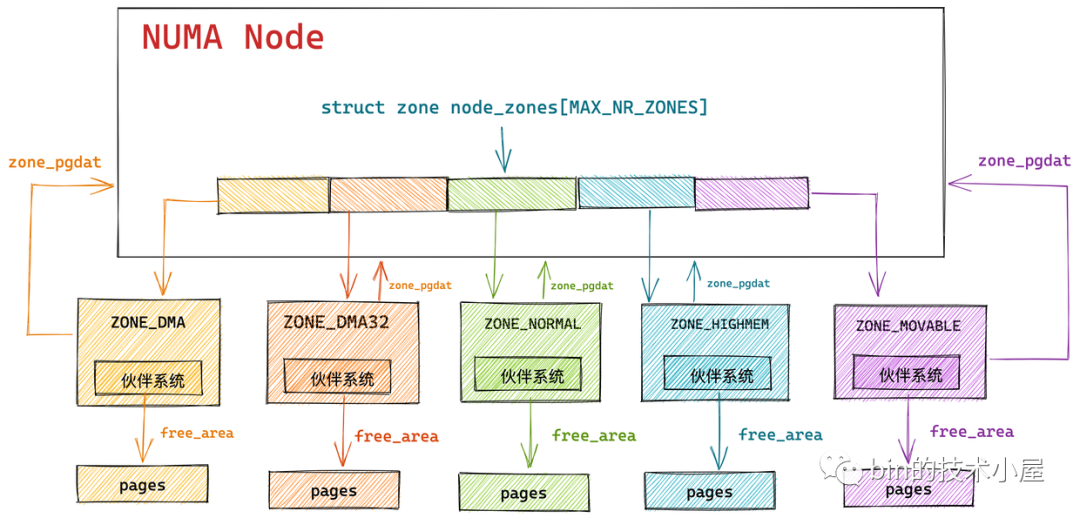
ZONE
buddy_system(伙伴系统)管理
- ZONE_DMA:用于 DMA(直接内存访问)的内存区域,通常是低地址范围的内存(比如 0-16MB),供需要直接访问内存的设备使用。
- ZONE_NORMAL:普通内存区域,通常是系统中大部分内存的区域(比如 16MB-896MB),用于内核和用户进程的常规内存分配。
- ZONE_HIGHMEM:高端内存区域,通常是超出内核直接映射范围的内存(比如 896MB 以上)。内核需要通过临时映射来访问这部分内存。
struct zone {
/* 只读为主的字段 */
/* 区域水位线,使用 *_wmark_pages(zone) 宏访问 分为high, low, min.*/
unsigned long _watermark[NR_WMARK];
unsigned long watermark_boost;
unsigned long nr_reserved_highatomic;
unsigned long nr_free_highatomic;
long lowmem_reserve[MAX_NR_ZONES];//保留的内存,防止高级内存去抢占低级内存(更重要,如DMA)
#ifdef CONFIG_NUMA
int node; //zone在NUMA架构里所属的node
#endif
struct pglist_data *zone_pgdat;//指针,指向自己所属的NODE节点
struct per_cpu_pages __percpu *per_cpu_pageset; //冷热页机制
struct per_cpu_zonestat __percpu *per_cpu_zonestats;
/*
* high 和 batch 值会被复制到每个 CPU 的页面集(pageset)中,以加快访问速度
*/
int pageset_high_min;
int pageset_high_max;
int pageset_batch;
#ifndef CONFIG_SPARSEMEM
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn; //zone起始的物理帧地址
atomic_long_t managed_pages; //zone在buddy system里的page数量
unsigned long spanned_pages; //zone里包含的页面数(包含空洞)
unsigned long present_pages;
#if defined(CONFIG_MEMORY_HOTPLUG)
unsigned long present_early_pages;
#endif
#ifdef CONFIG_CMA
unsigned long cma_pages;
#endif
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* 隔离页面块的数量。用于解决由于竞争性地获取页面块的迁移类型
* 导致的空闲页面计数错误问题。由 zone->lock 保护。
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* 参见 spanned/present_pages 的更多描述 */
seqlock_t span_seqlock;
#endif
int initialized;
/* 页面分配器使用的写密集字段 */
CACHELINE_PADDING(_pad1_);
struct free_area free_area[NR_PAGE_ORDERS]; //buddy system的链表
#ifdef CONFIG_UNACCEPTED_MEMORY
/* 待接受的页面。列表中的所有页面都是 MAX_PAGE_ORDER 大小 */
struct list_head unaccepted_pages;
/* 当区域中的最后一个页面被接受后调用 */
struct work_struct unaccepted_cleanup;
#endif
/* 区域标志位,见下方 */
unsigned long flags;
spinlock_t lock; //保护free_area,加锁操作
/* 下次 trylock 成功时要释放的页面 */
struct llist_head trylock_free_pages;
/* 用于页面压缩和虚拟内存统计的写密集字段 */
CACHELINE_PADDING(_pad2_);
/*
* 当空闲页面低于此点时,读取空闲页面数时会采取额外的步骤,
* 以避免每 CPU 计数器漂移导致水位线被突破
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* 页面压缩空闲扫描器应开始的 PFN */
unsigned long compact_cached_free_pfn;
/* 页面压缩迁移扫描器应开始的 PFN */
unsigned long compact_cached_migrate_pfn[ASYNC_AND_SYNC];
unsigned long compact_init_migrate_pfn;
unsigned long compact_init_free_pfn;
#endif
#ifdef CONFIG_COMPACTION
/*
* 在页面压缩失败时,跳过 1<<compact_defer_shift 次压缩尝试
* 后再重试。自上次失败以来尝试的次数由 compact_considered 跟踪。
* compact_order_failed 是压缩失败的最小阶。
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* 当 PG_migrate_skip 位需要被清除时设置为 true */
bool compact_blockskip_flush;
#endif
bool contiguous;
CACHELINE_PADDING(_pad3_);
/* 区域统计 */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_event[NR_VM_NUMA_EVENT_ITEMS];
} ____cacheline_internodealigned_in_smp;
direct reclaim是指在系统内存不足时且zone到达MIN水位线时,当前进程直接介入内存回收的过程。具体来说,当系统可用内存(free内存量)低于最低水位线(min watermark)时,如果新的内存申请无法得到满足,系统会进入direct reclaim模式。
kswapd woken up是指在LOW水位线时,唤醒kswapd,以执行内存回收操作。
free_area 中每个项并非只有一个双向链表,而是按照不同的“迁移类型”(migrate type)进行分开存放
在多核处理器中,多个 CPU 会并发访问 struct zone,为了防止并发访问,内核使用了一把 spinlock_t lock 自旋锁来防止并发错误以及不一致。
LRU和free_area由每个zone为单位单独维护一个
PAGE
通过slab allocator(SLAB分配器)管理
struct page 是 Linux 内核中表示单个物理页面(Page)的结构体。页面是内存管理的最小单位,通常是 4KB(取决于体系结构)。
PFN 与 struct page 是一一对应的关系,内核提供了两个宏来完成 PFN 与 物理页结构体 struct page 之间的相互转换。它们分别是 page_to_pfn 与 pfn_to_page。
struct page {
unsigned long flags; /* 原子标志位,部分可能异步更新 */
//联合体内所有字段互斥、联合体的大小由其最大的成员决定,且同一时刻只能使用一个成员。
//2
union {
//2.1
//页面缓存页面(文件数据缓存)或匿名页面(用户进程内存),用于管理页面回收(LRU 链表)、映射(mapping 和 index)、私有数据(private),以及空闲 //页面管理(buddy_list、pcp_list)。
struct { //这个结构体一共5个机器字
/* @lru: 用于页面回收的链表,例如 active_list,由 lruvec->lru_lock 保护。
//2.1.1
union { //这个联合体2个机器字
struct list_head lru; //正在使用中的页面,会通过lru回收
struct {
/* 始终为偶数,以避免 PageTail 的误判 */
void *__filler;
/* 统计页面或 folio 的 mlock 计数 */
unsigned int mlock_count;
};
/* 或者,空闲页面 */
struct list_head buddy_list; //已经回收的页面,在buddy system的链表中
struct list_head pcp_list;
struct {
struct llist_node pcp_llist;
unsigned int order;
};
};
//文件页(0)匿名页(1),指向page_cache或者vma
struct address_space *mapping;
//2.1.3
union {
pgoff_t index; //文件页为索引,匿名页为vma索引
unsigned long share; /* fsdax 的共享计数 */
};
unsigned long private;
};
//2.2
struct {
/**
* 由网络子系统(Network Stack)通过 page_pool 分配的页面,用于高效处理网络数据
*DMA 映射(dma_addr)、引用计数(pp_ref_count)。
*/
unsigned long pp_magic;
struct page_pool *pp;
unsigned long _pp_mapping_pad;
unsigned long dma_addr;
atomic_long_t pp_ref_count;
};
//2.3
struct { /* 复合页面的尾页面 */
unsigned long compound_head; /* 指向复合页面的头页面 */
};
//2.4
struct { //设备内存页面(ZONE_DEVICE)
void *_unused_pgmap_compound_head;
void *zone_device_data;
/*
* ZONE_DEVICE 私有页面被视为已映射,因此接下来的三个字
* 保存映射、索引和私有字段,这些字段来自源匿名页面或页面缓存页面,
* 在页面迁移到设备私有内存期间使用。
* ZONE_DEVICE MEMORY_DEVICE_FS_DAX 页面在映射 pmem 支持的 DAX 文件时,
* 也会使用映射、索引和私有字段。
*/
};
//2.5
//待通过 RCU 释放的页面。
struct rcu_head rcu_head;
};
union { /* 此联合体大小为4字节 */
unsigned int page_type;
atomic_t _mapcount;//被多少进程映射,初始为-1
};
atomic_t _refcount;//被多少进程引用,初始值为0
.
.
.
} _struct_page_alignment;
我们看到,第二个联合体有五个互斥的页面类型
1、struct page 联合体包含 5 种页面类型:
页面缓存和匿名页面(包含 lru 字段,用于 LRU 链表)。
网络栈页面(page_pool)。
复合页面的尾页面。
ZONE_DEVICE 页面。
RCU 释放页面。
2、lru和buddy_list互斥:
union { //这个联合体2个机器字
struct list_head lru; //正在使用中的页面,会通过组织成链表,lru回收,flag的PG_lru通常置位
...
/* 或者,空闲页面 */
struct list_head buddy_list; //已经回收的页面,在buddy system的链表中,flag的PG_buddy通常置位
}
3、大页面和复合页面
在 Linux 内核中,大页面通常由 hugetlbfs 文件系统管理(HugeTLB 大页面),或者通过透明大页面(Transparent Huge Pages, THP)实现。
复合页面是内核中一组连续物理页面的逻辑集合,由一个头部页面(head page)和多个尾页面(tail page)组成,除了头页面全是尾页面。
复合页面是内核用来实现大页面的一种机制,但不是唯一方式,还有直接使用 Buddy System 分配的页面块、或者组织成一个自定义页面池的方式
enum pageflags {
PG_locked, //页被锁,无法访问(可能有人正在使用)
PG_referenced, //页最近被引用
PG_uptodate, //页被加载进入内存
PG_dirty, //页被修改过
PG_lru, //表示页在lru的哪个链表
PG_active, //页是否active
PG_slab, //页在slab中
PG_reserved, //
PG_compound, //复合页
PG_private, //private结构体指向了具体的对象
PG_writeback, //被写回磁盘
PG_reclaim, //页被reclaim回收
#ifdef CONFIG_MMU
PG_mlocked, //页被锁在内存里
PG_swapcache = PG_owner_priv_1,
PG_head, //复合页的第一页
................
};
page为了节省内存使用很多标志位表示其状态,
LRU
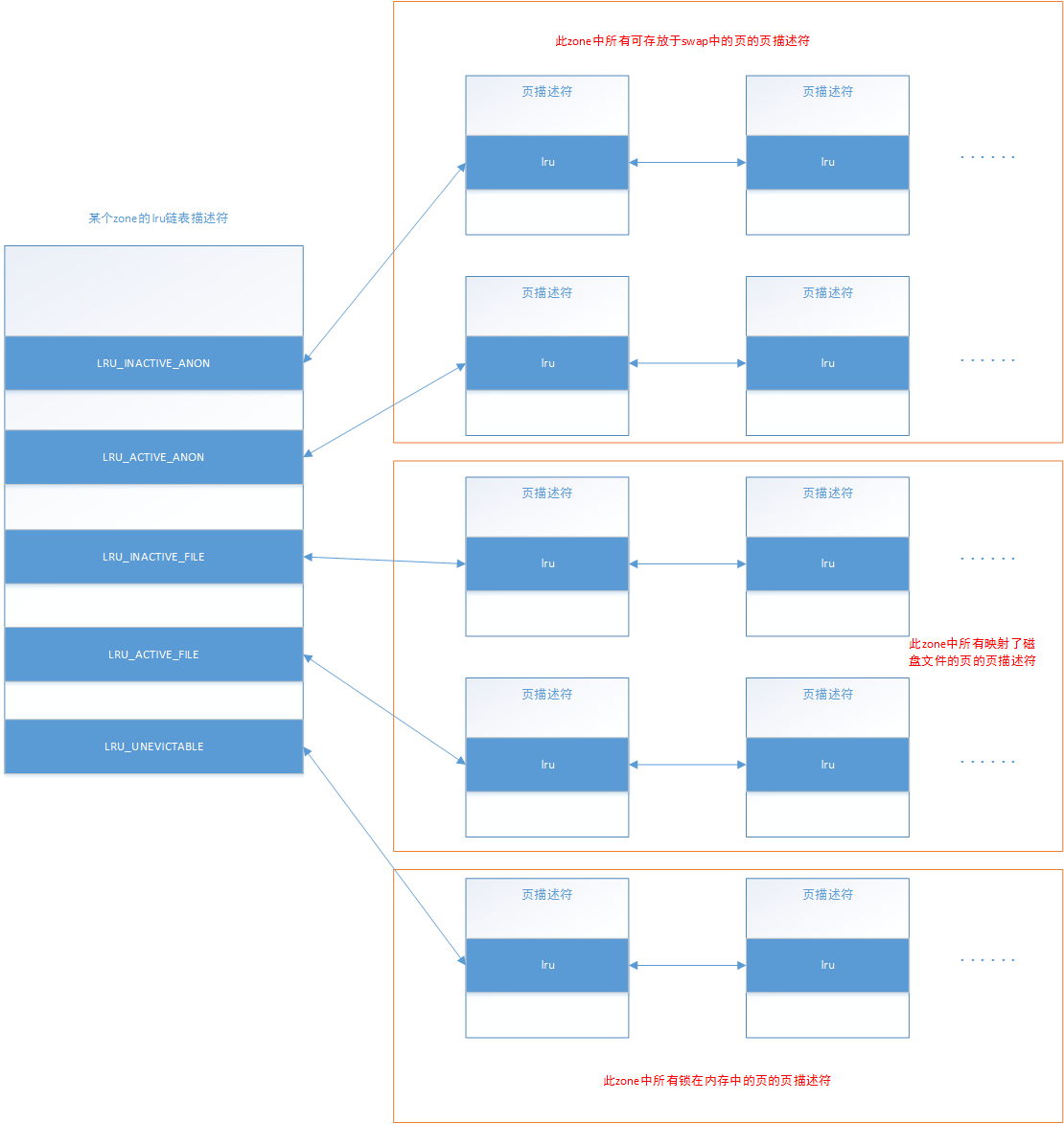
物理内存区域中的内存回收分为文件页回收(通过 pflush 内核线程,脏页写回,未修改直接丢弃)和匿名页回收(通过 kswapd 内核进程)。
回收优先级为:inactive 链表尾部 > inactive 链表头部 > active 链表尾部 > active 链表头部
工作原理如下:
- 对于文件页来说,当它被第一次读取的时候,内核会将它放置在 inactive 链表的头部,如果它继续被访问,则会提升至 active 链表的尾部。如果它没有继续被访问,则会随着新文件页的进入,内核会将它慢慢的推到 inactive 链表的尾部,如果此时再次被访问则会直接被提升到 active 链表的头部。大家可以看出此时页面的使用频率这个因素已经被考量了进来。
- 对于匿名页来说,当它被第一次读取的时候,内核会直接将它放置在 active 链表的尾部,注意不是 inactive 链表的头部,这里和文件页不同。因为匿名页的换出 Swap Out 成本会更大,内核会对匿名页更加优待。当匿名页再次被访问的时候就会被被提升到 active 链表的头部。
- 当遇到内存紧张的情况需要换页时,内核会从 active 链表的尾部开始扫描,将一定量的页面降级到 inactive 链表头部,这样一来原来位于 inactive 链表尾部的页面就会被置换出去。
进程可以通过 mlock() 等系统调用把内存页锁定在内存里,保证该内存页无论如何不会被置换出去,比如出于安全或者性能的考虑,页面中可能会包含一些敏感的信息不想被 swap 到磁盘上导致泄密,或者一些频繁访问的内存页必须一直贮存在内存中。当这些被锁定在内存中的页面很多时,内核在扫描 active 链表的时候也不得不跳过这些页面,所以内核又将这些被锁定的页面单独拎出来放在一个独立的链表中。
SPARSEMEM 稀疏内存模型
热插拔:物理内存可以动态的从主板中插入以及拔出
早期的linux内存模型假设的是内存连续(FLAT内存模型)使用数组存储页号PFN,或者偶尔才存在空洞(DISCONTIG内存模型)采用node管理数组。然而为了支持热插拔使得内存空洞变为常态….
SPARSEMEM 稀疏内存模型的核心思想就是对粒度更小的连续内存块进行精细的管理,用于管理连续内存块的单元被称作 section 。section管理pages,而section本身也作为数组被管理。
NUMA模型
由于多CPU的出现,多个CPU共用一根总线势必会造成总线的带宽不够用的情况。为了解决此,设计师干脆给每个CPU单独划分了一个属于自己的内存区域。
每个NODE由pglist_data* node_data这个数组集合管理。
typedef struct pglist_data {
// NUMA 节点id
int node_id;
// 指向 NUMA 节点内管理所有物理页 page 的数组
struct page *node_mem_map;
// NUMA 节点内第一个物理页的 pfn
unsigned long node_start_pfn;
// NUMA 节点内所有可用的物理页个数(不包含内存空洞)
unsigned long node_present_pages;
// NUMA 节点内所有的物理页个数(包含内存空洞)
unsigned long node_spanned_pages;
// 保证多进程可以并发安全的访问 NUMA 节点
spinlock_t node_size_lock;
...
// NUMA 节点中的物理内存区域个数
int nr_zones;
// NUMA 节点中的物理内存区域
struct zone node_zones[MAX_NR_ZONES];
// NUMA 节点的备用列表
struct zonelist node_zonelists[MAX_ZONELISTS];
...
// 页面回收进程:ZONE水位线机制
struct task_struct *kswapd;
wait_queue_head_t kswapd_wait;
// 内存规整进程:防止形成内存碎片
struct task_struct *kcompactd;
wait_queue_head_t kcompactd_wait;
} pg_data_t;
冷热页机制
为了加快CPU的访存速度,引入了高速缓存,对于高速缓存内的页面管理被叫做冷热页机制。
struct per_cpu_pages __percpu *per_cpu_pageset; //冷热页结构体链表
struct per_cpu_pages {
int count; //集合里页的数量
int high; //高速缓存最多的页数量,如果超过了这个值就要把热页放回物理内存
int batch; //触发放回机制后每次放回batch个
struct list_head list; //页的双向链表
};
内存分配/释放相关函数
①分配
返回值是一个struct page的结构体指针,不是虚拟地址。
struct page *alloc_pages(gfp_t gfp, unsigned int order);
与上面函数类似,但是只申请一张内存页
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
返回的是内存的虚拟地址指针
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
只分配一个内存页,但是其中内容全部置0
unsigned long get_zeroed_page(gfp_t gfp_mask){return __get_free_pages(gfp_mask | __GFP_ZERO, 0);}
分配dma的内存页
unsigned long __get_dma_pages(gfp_t gfp_mask, unsigned int order);
②释放
void __free_pages(struct page *page, unsigned int order); //通过struct page结构体释放
void free_pages(unsigned long addr, unsigned int order); //使用虚拟地址释放
③gfp
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA32
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_MOVABLE 0x08u
④__alloc_pages函数(最最最底层的分配函数,一切的源头)
struct alloc_context {
// 运行进程 CPU 所在 NUMA 节点以及其所有备用 NUMA 节点中允许内存分配的内存区域
struct zonelist *zonelist;
// NUMA 节点状态掩码
nodemask_t *nodemask;
// 内存分配优先级最高的内存区域 zone
struct zoneref *preferred_zoneref;
// 物理内存页的迁移类型分为:不可迁移,可回收,可迁移类型,防止内存碎片
int migratetype;
// 内存分配最高优先级的内存区域 zone
enum zone_type highest_zoneidx;
// 是否允许当前 NUMA 节点中的脏页均衡扩散迁移至其他 NUMA 节点
bool spread_dirty_pages;
};
enum migratetype {
MIGRATE_UNMOVABLE, //不能随意移动,对应DMA的页
MIGRATE_MOVABLE, //可以随意移动,一般是用户空间的页
MIGRATE_RECLAIMABLE, //不能移动,但是可以删除(一般是文件页)
MIGRATE_PCPTYPES, //每个cpu的页缓存(冷热页机制)
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
MIGRATE_CMA, //预留的物理内存,一般给DMA使用
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, //不可以从链表分配
#endif
MIGRATE_TYPES
};
快速分配路径:get_page_from_freelis函数找到可用的内存,直接返回。
慢速分配路径:__alloc_pages_slowpath函数。
OOM机制
当内存分配经过了reclaim和compact之后仍然无法分配内存的时候,启动oom杀死得分最高的进程,释放其所有的页。
BUDDY_SYSTEM
分配
若对应大小没有可分配内存块,则从低阶向上查找,找到后分裂成合适大小。
如果当前 NUMA 节点无法满足内存分配时,内核会跨越 NUMA 节点从其他节点上分配内存。当伙伴系统中指定的迁移列表 free_list[MIGRATE_TYPE] 无法满足内存分配需求时,内核根据不同迁移类型定义: (fallbacks是从高阶向低阶查找)
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
释放
会在释放内存块的大小查找相同大小且内存连续的“伙伴”合并升阶,直到无法找到伙伴与之合并为止。
其他
从 CPU 高速缓存列表中获取内存页:内核对只分配一页物理内存的情况做了特殊处理,当只请求一页内存时,内核会借助 CPU 高速缓存冷热页列表 pcplist 加速内存分配的处理,此时分配的内存页将来自于 pcplist 而不是伙伴系统。
KMALLOC
kmalloc 内存池体系的底层基石是基于 slab alloactor 体系构建的,其本质其实就是各种不同尺寸的通用 slab cache。
const struct kmalloc_info_struct kmalloc_info[] __initconst = {
{NULL, 0}, {"kmalloc-96", 96},
{"kmalloc-192", 192}, {"kmalloc-8", 8},
{"kmalloc-16", 16}, {"kmalloc-32", 32},
{"kmalloc-64", 64}, {"kmalloc-128", 128},
{"kmalloc-256", 256}, {"kmalloc-512", 512},
{"kmalloc-1k", 1024}, {"kmalloc-2k", 2048},
{"kmalloc-4k", 4096}, {"kmalloc-8k", 8192},
{"kmalloc-16k", 16384}, {"kmalloc-32k", 32768},
{"kmalloc-64k", 65536}, {"kmalloc-128k", 131072},
{"kmalloc-256k", 262144}, {"kmalloc-512k", 524288},
{"kmalloc-1M", 1048576}, {"kmalloc-2M", 2097152},
{"kmalloc-4M", 4194304}, {"kmalloc-8M", 8388608},
{"kmalloc-16M", 16777216}, {"kmalloc-32M", 33554432},
{"kmalloc-64M", 67108864}
};
分配块
static u8 size_index[24] __ro_after_init = {
3, /* 8 */
4, /* 16 */
5, /* 24 */
5, /* 32 */
6, /* 40 */
6, /* 48 */
6, /* 56 */
6, /* 64 */
1, /* 72 */
1, /* 80 */
1, /* 88 */
1, /* 96 */
7, /* 104 */
7, /* 112 */
7, /* 120 */
7, /* 128 */
2, /* 136 */
2, /* 144 */
2, /* 152 */
2, /* 160 */
2, /* 168 */
2, /* 176 */
2, /* 184 */
2 /* 192 */
};
文件系统
操作系统的文件数据除了实际内容之外,通常含有非常多的属性,例如Linux操作系统的文件权限与文件属性。文件系统通常会将这两部分内容分别存放在inode和block中。
inode 和 block 概述
文件是存储在硬盘上的,硬盘的最小存储单位叫做扇区sector,每个扇区存储512字节。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个块block。这种由多个扇区组成的块,是文件存取的最小单位。块的大小,最常见的是4KB,即连续八个sector组成一个block。
文件数据存储在块中,那么还必须找到一个地方存储文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种存储文件元信息的区域就叫做inode,中文译名为索引节点,也叫i节点。因此,一个文件必须占用一个inode,但至少占用一个block。
- 元信息 → inode
- 数据 → block
inode 内容
inode包含很多的文件元信息,但没有文件名,例如:字节数、属主UserID、属组GroupID、读写执行权限、时间戳等。
而文件名存放在目录当中,但Linux系统内部不使用文件名,而是使用inode号码识别文件。对于系统来说文件名只是inode号码便于识别的别称。
挂载
在一个区被格式化为一个文件系统之后,它就可以被Linux操作系统使用了,只是这个时候Linux操作系统还找不到它,所以我们还需要把这个文件系统「注册」进Linux操作系统的文件体系里,这个操作就叫「挂载」 (mount)。 挂载是利用一个目录当成进入点(类似选一个现成的目录作为代理),将文件系统放置在该目录下,也就是说,进入该目录就可以读取该文件系统的内容,类似整个文件系统只是目录树的一个文件夹(目录)。 这个进入点的目录我们称为「挂载点」。
由于整个 Linux 系统最重要的是根目录,因此根目录一定需要挂载到某个分区。
超级块 是文件系统的 元信息结构,每个挂载的文件系统都对应一个 super_block。
它描述了这个文件系统的整体结构,比如:
- 块大小
- inode 总数、位图位置
- 挂载状态、magic number(用于识别 FS 类型)
- 文件系统操作函数(super_operations)
伪文件系统
例如ptyfs、devfs、sysfs和procfs
消息&消息队列
msg_quene结构体
/* one msq_queue structure for each present queue on the system */
struct msg_queue {
struct kern_ipc_perm q_perm;
time64_t q_stime; /* last msgsnd time */
time64_t q_rtime; /* last msgrcv time */
time64_t q_ctime; /* last change time */
unsigned long q_cbytes; /* current number of bytes on queue */
unsigned long q_qnum; /* number of messages in queue */
unsigned long q_qbytes; /* max number of bytes on queue */
struct pid *q_lspid; /* pid of last msgsnd */
struct pid *q_lrpid; /* last receive pid */
struct list_head q_messages;
struct list_head q_receivers;
struct list_head q_senders;
} __randomize_layout;
msg_msg
/* one msg_msg structure for each message */
struct msg_msg {
struct list_head m_list;
long m_type;
size_t m_ts; /* message text size */
struct msg_msgseg *next;
void *security;
/* the actual message follows immediately */
};
- msgget:创建一个消息队列
#include <sys/msg.h>
...
int msgget(key_t key, int msgflg);
key:id(int)或者是IPC_PRIVATE(每次创建一个新队列), msgflg:权限,msgflg可以与IPC_CREAT做或操作表示当key所命名的消息队列不存在时创建一个消息队列
ftok("/tmp", 'B');: ftok (“File to Key”) 函数根据一个已存在的文件路径 (/tmp) 和一个项目ID ('B') 生成一个唯一的键。只要路径和ID不变,任何调用ftok的进程都会得到相同的key,从而可以访问同一个消息队列。
- msgsnd:向指定消息队列发送消息
struct msgbuf {
long mtype;
char mtext[80];
};
int msgsnd(int msqid, struct msgbuf *msgp, size_t msgsz, int msgflg);
msgid:由msgget创建的queneid, msgp:指向创建的msgbuf, msgsz:发送的mtext的大小, msgflg=0
- msgrcv:从指定消息队列接接收消息
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,int msgflg);
msqid:消息的id, msgp:接收缓冲区, msgsz:接受大小
msgtype:
* =0 : 接收第一个消息
* >0: 接收类型等于msgtype的第一个消息
* <0: 接收类型等于或者小于msgtype绝对之的第一个消息
例子:
msgrcv(ms_qid[0], buf, 0x1000 - 0x30, 0, IPC_NOWAIT | MSG_NOERROR | MSG_COPY);